- 89 Posts
- 95 Comments

 2·4 months ago
2·4 months agoThat confirms it then: it’s a client feature. I also have a dbzer0 acct as you do, but I only see the total, which apparently can be attributed to the stock web client.
The only relevant user setting I have is “show scores”. False shows no scores at all for comments and threads. True shows up votes and down votes on comments, but not threads. So if lemm.ee shows you up and down votes on threads and you are using the web client, then that must be a server-side option or mod. It could be a client capability but I’ve not found a worthy 3rd party client for Lemmy yet (for the desktop).
!isitdown@infosec.pub is a better place for this info.
And speaking of replacement links, we need a way to add them and have the alternative links voted on, and ultimately the replacement link should potentially outrank the original link and take the spotlight. I will add this to the OP.
Perhaps. Simplicity is important. But what if I circumvent the exclusivity of an article by finding a mirrored copy on archive.org? If the content is quite insighful, would then want to say it is both exclusive and insightful. Those metrics together could then be used to work out whether it’s worthwhile to find a replacement source for the same content.
Which is almost as ridiculous as acting like an admin shouldn’t be able to ban someone from their instance.
The admin did not know why they were suppressing the messages. Apparently they did not keep notes. So they reversed the action. But no one here said admins should not have the power to ban. Quite the contrary: they should. And because they should have that power, it should not be disproportionate. One million people should not lose access to civil posts from Bob because Mallory the admin did not like one of Bob’s ideas. This is why decentralisation is important.
Your account is 3 years old (strangely almost no posts or comments though)
Then your view is being restricted¹. I don’t know how sheltering lemmyworld admins are of their users generally but the Mastodon analog to #lemmyworld would be mastodon.social, and mastodon.social is quite loose with the censor button. There have been conversations where people only saw part of the conversation and were confused because they knew someone else was engaged but they could not see the whole conversation. After investigation, it was not a federation issue but in fact the mastodon.social admin simply decided to block a particular person. I would not be surprised if lemmyworld were blocking me in some way because anyone who outspokenly advocates for decentralisation is directly undermining lemmyworld’s position (lemmyworld is centralised both by Cloudflare and also by disproportionate userbase).
and I’ve noticed the people that were here before everyone else seems to hate the new wave of people that showed up a year ago
The fediverse was created out of love for a #decentralised free world. Centralised nodes like #LemmyWorld, #FBThreads, #shItjustWorks, #LemmyCA, #LemmyOne, etc work against the philosophy of decentralisation. Users on those nodes are either not well informed about the problems of concentrated imbalances of power, or they simply do not care and do not value digital rights; they only care about their personal reach. Fixing the bug reported here addresses the former (uninformed users).
The bug report herein is specifically designed to be an inclusive alternative to what you suggest, which is:
Why don’t you just convince your admin to defederate? Or go make you own instance for just people you agree with?
Locking people out on the crude basis of which node they come from is somewhat comparable to what Cloudflare (and lemmyworld) does by discriminating against people on the crude basis of IP reputation. It over selects and under selects at the same time if the goal is to separate good links from bad links. Anyone can post a shitty link. A majority of shitty links would come from the lemmyworld crowd, but it’s not a good criteria for a spam/ham separation. The fedi needs to improve by tagging bad links appropriately, which should not be influenced by the host the author uses.
¹(edit) you should see over 400 posts and comments. Visit https://sopuli.xyz/u/freedomPusher to see the real figures.
It’s not a bug if it works as designed.
What you claim here is that software cannot have a defective design. Of course you have design defects. These are the hardest to correct.
I’d also accept “it used to do this and it doesn’t any more and not on purpose”.
This is conventional wisdom. Past behavior is no more an indication of correctness than defectiveness. GREP’s purpose was to process natural language. A line feed is not a sensible terminator in that application. For 50 years people just live with the limitation or they worked around it. Or they adapt to single token searches. It does not cease to be defect because workarounds were available.
that doesn’t make it a bug if it was never designed in to the program.
The original design was implemented on an extremely resource-poor system by today’s standards, where 64k was HUGE amount of space. It was built to function under limitations that no longer exist. I would say the design is not defective so long as your target platform is a PDP-11 from the 1970s. Otherwise the design should evolve along with the tasks and machines.
If all you’re advocating for is allowing grep to use some other character as a delimeter, I might be able to get behind something like bash’s $IFS or awk’s $FS variable (maybe). But I couldn’t get behind anything backwards-incompatible.
Of course. GREP has an immeasurable number of scripts dependant on it worldwide going back 50 years and it’s among Debian’s 23 essential packages:
dpkg-query -Wf '${Package;-40}${Essential}\n' | grep yesChanging grep’s default behavior now would bring the world down. Dams would shatter. Nuclear power plants would melt down. Traffic lights would go berzerk. It would be like a Die Hard 3 “firesale”. Planes would fall out of the sky. Skynet would come online and wipe us all out. It would have to be a separate option.
TIL there are people who (try to) use grep for natural language.
The very first task grep was created for is specifically natural language input. Search “Federalist Papers grep”. There’S also a short documentary about this out in the wild somewhere but I don’t have any link handy.
Oh, and this is 100% feature/enhancement request territory. Not a bug report in any sense.
This is conventional wisdom coming from a viewpoint that simultaneously misses grep’s intended purpose.
But now that the defect has been rooted in for ~50 years, perhaps fair enough to leave grep alone. For me it depends on how lean the improvement could be. Boating grep out too much would not be favorable, but substantial replication of code between two different tools is also unfavorable. Small is good, but swiss army knives of tools also bring great value if they can be lean and internally simple.
I don’t know if you’re saying “because PDFGREP is good at handling natural language, grep should be too”
Not at all. They both have the same problem. But this same limitation in pdfgrep is a nuissance in more situations because PDFs are proportionally more likely to process natural language input.
Either way, I don’t follow how PDFGREP is relevant to discussions about grep
They have the same expression language and roughly same options. PDFGREP is most likely not much more than a grep wrapper that extracts the text from the PDF first.
grep isn’t really designed as a natural language search tool
My understanding of GREP history is that Ken Thompson created grep to do some textual analysis on The Federalist Papers, which to me sounds like it was designed for processing natural language. But it was on a PDP-11 which had resource constraints. Lines of text would be more uniform to manage than sentences given limited resources of the 1970s.
Thanks for the PERL code. Though I might favor sed or awk for that job. Of course that also means complicating emacs’ grep mode facility. And for PDFs I guess I’d opt for pdfgrep’s limitations over doing a text extraction on every PDF.
UPDATE: it just now happened again, but this time not with the admin account (@QuentinCallaghan@sopuli.xyz) but with another user account. I was refreshing my profile and the user @baltakatei@sopuli.xyz appeared in the profile pulldown position on the page with my profile. This time I had time to take a screenshot before it changed:
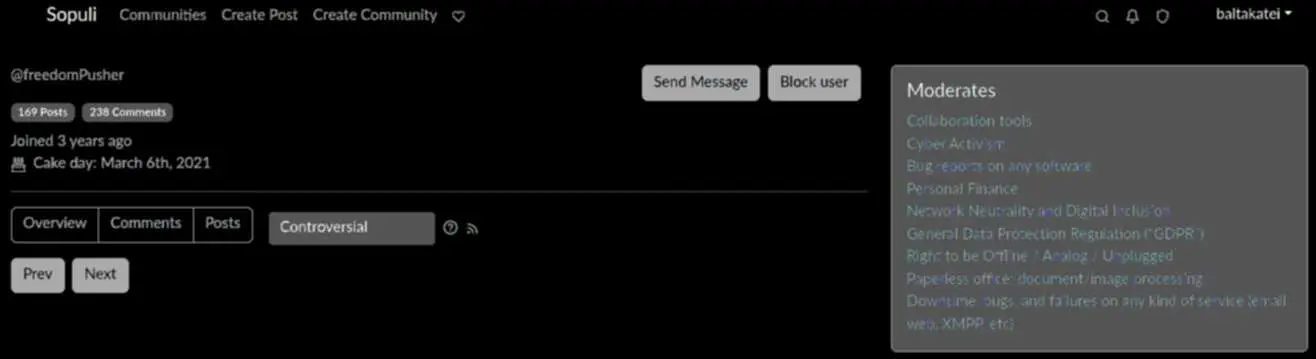
It’s interesting that it shows my profile page but not as I see it. That is, when I visit my own profile page I normally have a “subscribed” sidebar. This shows what someone else would see if they visit my profile while they are logged in, which still differs from what a logged out profile looks like (as send msg options were given). So I wonder if I could have sent myself a msg.
 1·4 months ago
1·4 months agoAfter reading the article it’s not as great as I was hoping for. From the article:
“We’re obviously going to be interested in having the books sell as successfully as possible, but we’re not going to harm the fundamental mission of the library to provide free and easy access to the content on our shelves. We’re not going to sacrifice that mission. Just because we’re operating Angel City Press, we’re not going to buy 500 copies of every title and put them in every branch library. That’s not prudent. That’s not what a good library would do.”
So it’s still a profit-driven press. This is a conflict of interest but the library seems confident they can negoiate that fairly.
I was hoping the press would become non-profit and then be used to print and distribute creative commons licensed content. I have a friend (who shall remain unnamed but who is well known) who would like to release their work into the commons and give up all rights apart from attribution. In principle a library-owned press would seem ideal. But I guess this is not the right tool for the job. It also seems the books this press will print are LA-specific anyway.
Mobile apps for this sort of thing is quite alien to me – out of sight and out of mind because I cannot imagine using a small screen and tiny keyboard for forums when I am all day sitting at a PC with proper keyboard. Although speech to text probably makes small device input a little more tolerable.
The small nodes are not dead, so I wonder if the activity and accounts on the disproportionately small nodes can be attributed largely to mobile app users.
{kind=link}
 42·5 months ago
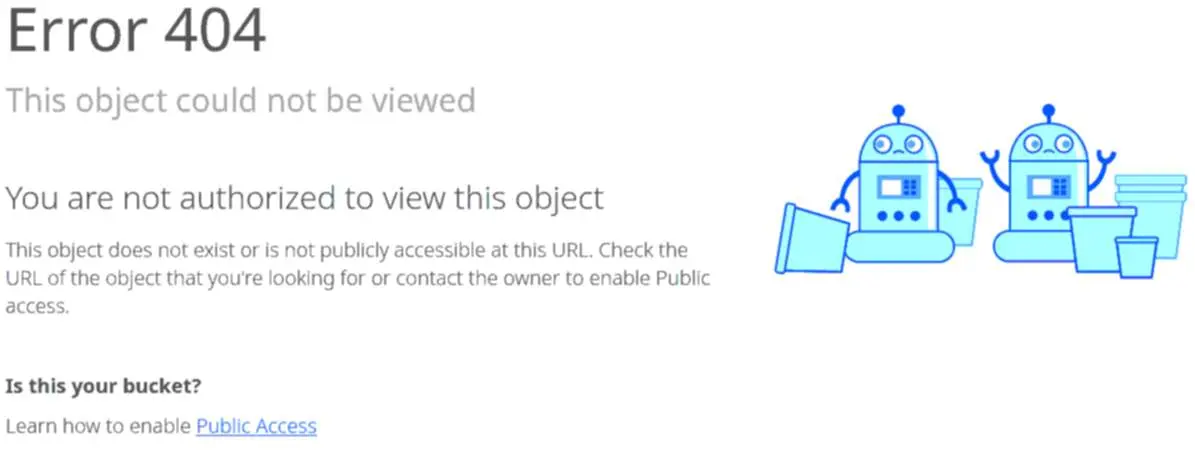
42·5 months agoI cannot see the image because it’s posted in the walled garden of #Cloudflare, which excludes me. Would someone please repost the image on an open-access instance or website so everyone can view it?
Just a tip, if you want to report this one in place that has a chance at being seen or forwarded into github,
gaupolhappens to be in the official Debian repos. So there is a debian bug tracker db which takes submissions via email, and there is also an Ubuntu bug db for it on Launchpad.Take that with a grain of salt though, especially if you don’t test it on debian or ubuntu before submission. Some Debian maintainers are willing to mirror the report upstream but most will ask you to do that (which you can refuse). Technically, the Debian rules favor upstream reports to be made to debian, but many maintainers ignore that guidance. Ubuntu maintainers tend to be less active. They won’t complain about upstream bug reports but at the same time the reports there tend to just sit idle AFAICT.
Law is driven by philosophy. When discussing high-level laws at the constitutional level and above (international/human rights), “law” loses effectiveness as such and becomes more of a philosophical guide. It’s not concrete when specific scenarios are not pinned down, and rarely enforced as a consequence. There is an abstract human right that we have freedom of religion, but national law can often contradict human rights.
There are no Amish communities in Europe (and AFAIk, no notable religions that oppose the digital transformation). So there would be not likely be national law that protects them. The question is hypothetical. Answering it requires understanding the meaning, purpose, and history of the freedom of religion, which itself would never be elaborated in law. The law is clean, hard and fast, without history and usually without rationale.
It’s an inherently philosophical question but with legal interplay. So it’s a 10,000 foot view question of how freedom of religion gets implemented in Europe. The philosophy cannot be neglected because it’s the driver.
Namely: Does Belgium law require agencies and companies to provide offline interfaces if a religion requires not using digital services/technology.
I would guess unlikely because there are no such religions in Belgium, AFAIK. The Amish would be in for a struggle. They would have to bring a complaint to court about digital transformation excluding them with no concrete law covering them, and try to cling to that rarely enforced body of human rights law. They might prevail in a high court, but what about someone who is not Amish, but who has the same moral objections? The Amish are Christians who morally object to lots of technology but strictly speaking the anti-tech is not really driven by Christianity. It’s more of a culture that is fused with their religion, which enables them to benefit from religious protections despite Christianity not being the driver. So a non-religious person who finds the forced use technology to be as unconscionable as an Amish practicioner would be equally oppressed, but would a court recognize this? Probably not, but if Amish were to arrive, then the question is would the law be written specifically to protect the Amish or would it be generalized enough that non-religious people would benefit? It’s all a question/prediction based on philosophy, psychology, law, and history.
 1·5 months ago
1·5 months agoStreetComplete shows me no map, just quests on a blank canvas. OSMand shows my offline maps just fine, but apparently StreetComplete has no way to reach the offline maps. I suppose that’s down to Android security – each app has it’s own storage space secure from other apps.
In principle, we should be able to put the maps on shared SD card space and both apps should access it. But StreetComplete gives no way in the settings of specifying the map location. And apparently it fails to fetch an extra copy of the maps as well in my case.
 1·7 months ago
1·7 months agoThey banned e-scooters in Paris? I’ve not heard that. Was it just the rentals or all e-scooters?
The article I referenced said Paris is banning noisy scooters, which would be motor scooters.
There is a new law that allows merchants to stop giving paper receipts.
The forced use of e-receipts in Europe (France, Belgium, Netherlands, Denmark, England, & Italy)